Improving TinaCloud Indexing with Native Git CLI and Sparse-Checkout
June 18, 2024
By Brook Jeynes
TinaCloud is now using the native Git CLI to clone repositories for indexing. This significantly reduces memory usage and improves performance for large repositories in the first part of the indexing process
If you're using TinaCMS, then you're most likely using TinaCloud. When not self-hosting TinaCMS, TinaCloud is the backend TinaCMS interacts with. It provides helpful features such as searching files. In order for Tina to do things like this, the content in your repo needs to be indexed.
Managing large-scale repositories presents a unique challenge for the team. The content indexing process was initially implemented using isomorphic-git, a Node.js-based Git solution. This approach worked well for most scenarios but as the use-case for Tina grew, so did repository sizes. Recently, we've had a user run into an out-of-memory (OOM) error when attempting to index their repository storing millions of files.
The root cause of these issues is that TinaCloud was downloading the entire repository contents, including all images and binary files, even though only a subset of these files were necessary for the indexing process. This led to substantial memory consumption and inefficiencies in the first part of the indexing process.
We're excited to announce a significant improvement in our content indexing process. By transitioning from a Node.js Git implementation to the native Git CLI, we've gained more control over the repository cloning and checkout process, enabling us to solve the out-of-memory issues effectively.
The key to this solution lies in leveraging Git's sparse-checkout feature in combination with many flags provided to the clone command, which allows us to specify exactly which files and directories to include in the working directory. We're able to read the Tina config file and only pull down what is required to index your project.
By implementing these changes, TinaCloud is now able to efficiently pull down only the files needed for indexing, significantly reducing memory usage and improving performance for large repositories in the first part of the indexing process.
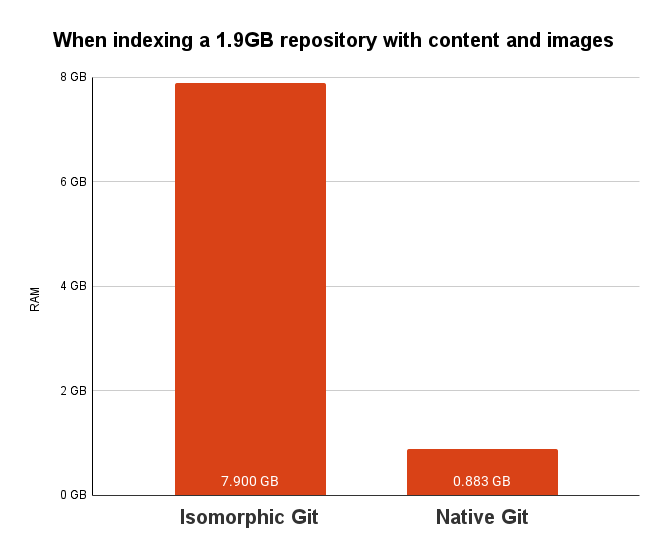
This enhancement marks a significant step forward in making TinaCloud more robust and efficient, ensuring that users can manage their content seamlessly, regardless of the size of their repositories.
We're thrilled to continue improving Tina and look forward to delivering more updates about what we're doing behind the scenes. If you have any feedback or questions, please feel free to reach out to our team via the Discord or visit our documentation for more information.
Last Edited: June 23, 2024